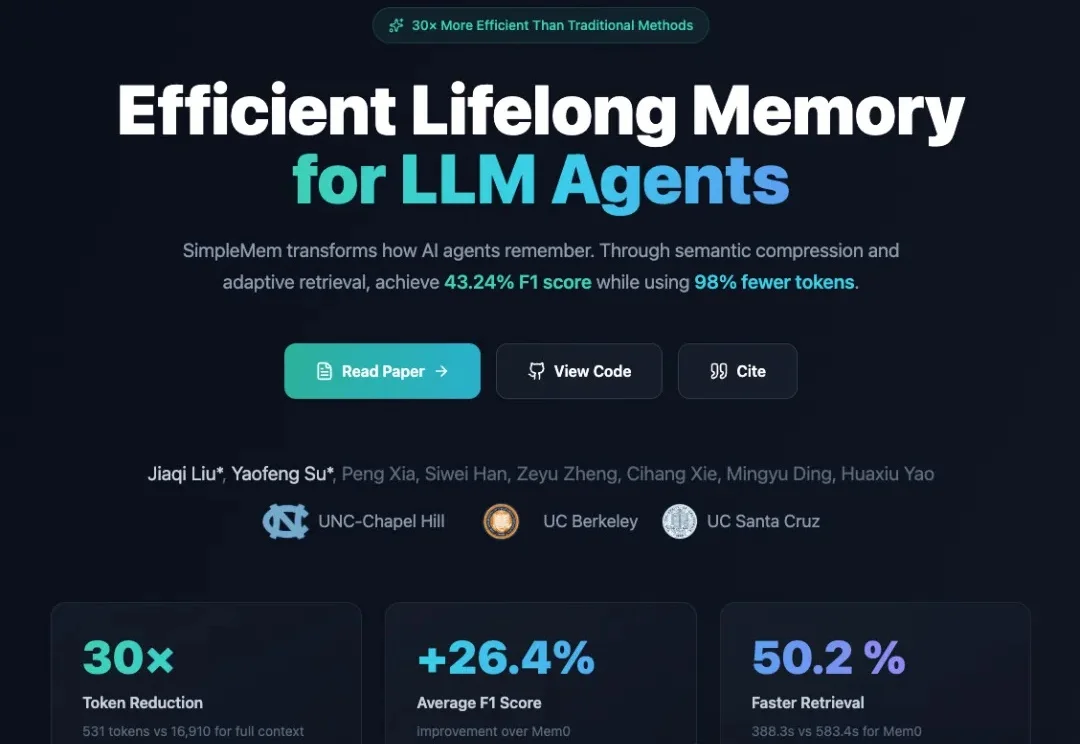
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA
让Agent记住一切是愚蠢的:SimpleMem用「结构化语义压缩」登顶记忆SOTA如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
来自主题: AI技术研报
9504 点击 2026-01-15 09:22
 搜索
搜索
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
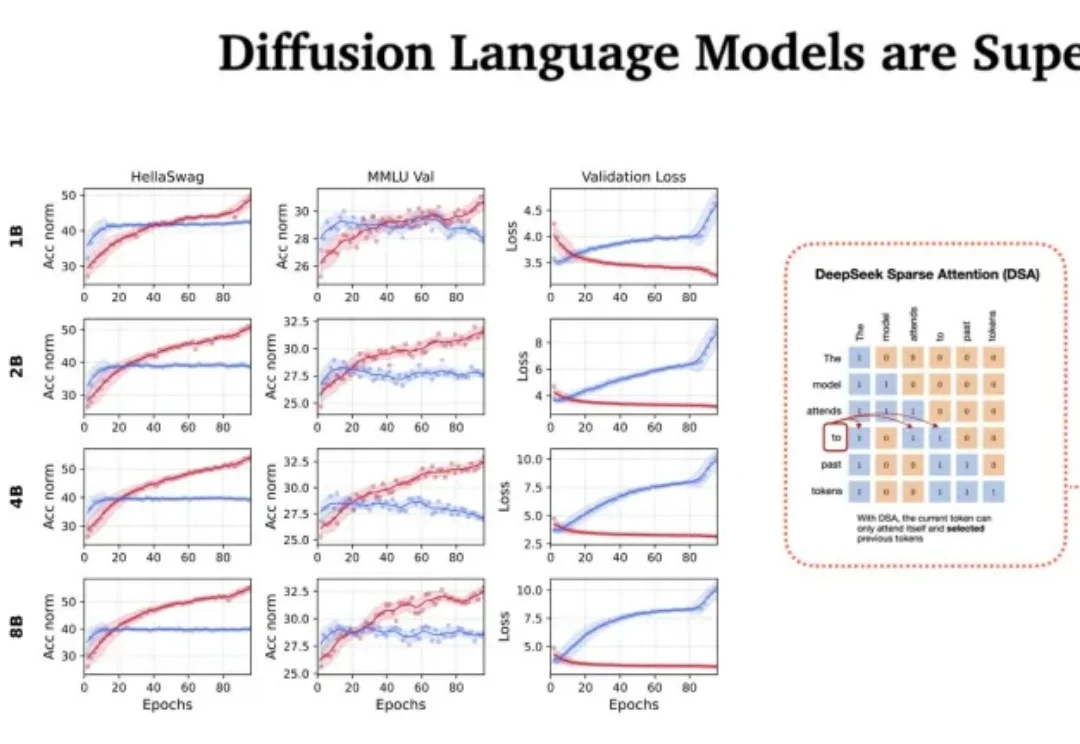
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
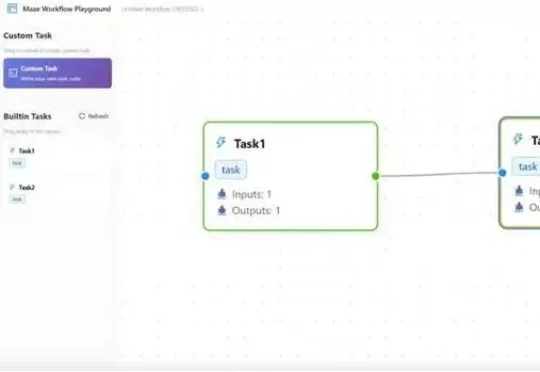
在大模型智能体(LLM Agent)落地过程中,复杂工作流的高效执行、资源冲突、跨框架兼容、分布式部署等问题一直困扰着开发者。而一款名为Maze的分布式智能体工作流框架,正以任务级精细化管理、智能资源调度、多场景部署支持等核心优势,为这些痛点提供一站式解决方案。
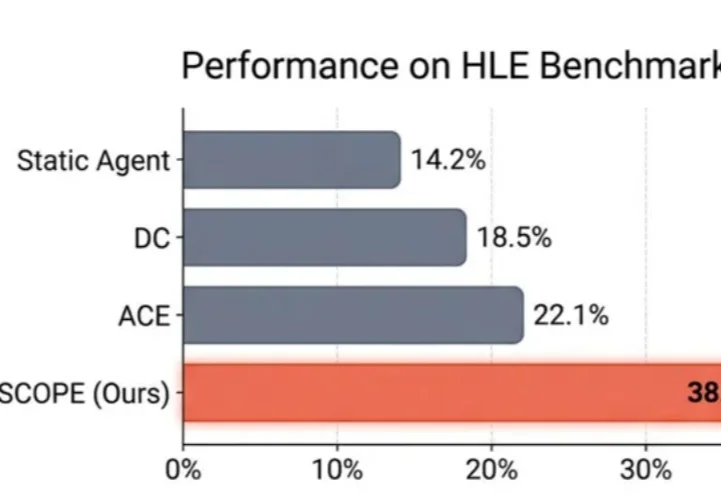
在 LLM Agent 领域,有一个常见的问题:Agent 明明 "看到了" 错误信息,却总是重蹈覆辙。

LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
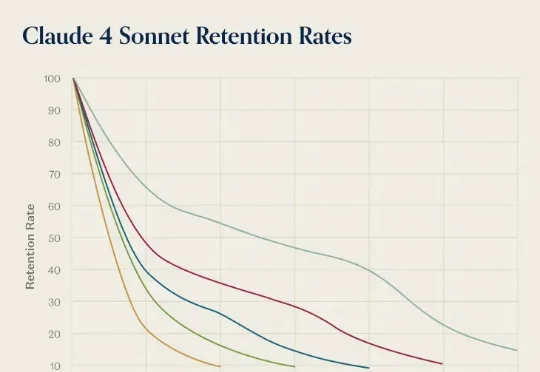
前几天,AI 推理服务供应商 OpenRouter 发布了一份报告《State of AI》,基于平台上 60 多家提供商的 300 多个模型,100 万亿个 token 的交互数据,对 LLM 的实际应用情况进行了分析。报告中,提到了一个「灰姑娘水晶鞋效应」,特别有意思。研究者在分析用户留用数据时发现一个现象:AI 模型发布第一个月进来的用户,往往比后来进来的用户留存率更高。
今年 10 月,专注构建世界模型的 General Intuition 完成了高达 1.34 亿美元的种子轮融资。这笔融资由硅谷传奇投资人 Vinod Khosla 领投,这是他自 2019 年首次投资 OpenAI 以来开出的最大单笔种子轮投资,也标志着他在 LLM 之后对下一代智能范式做出的一次重大下注。
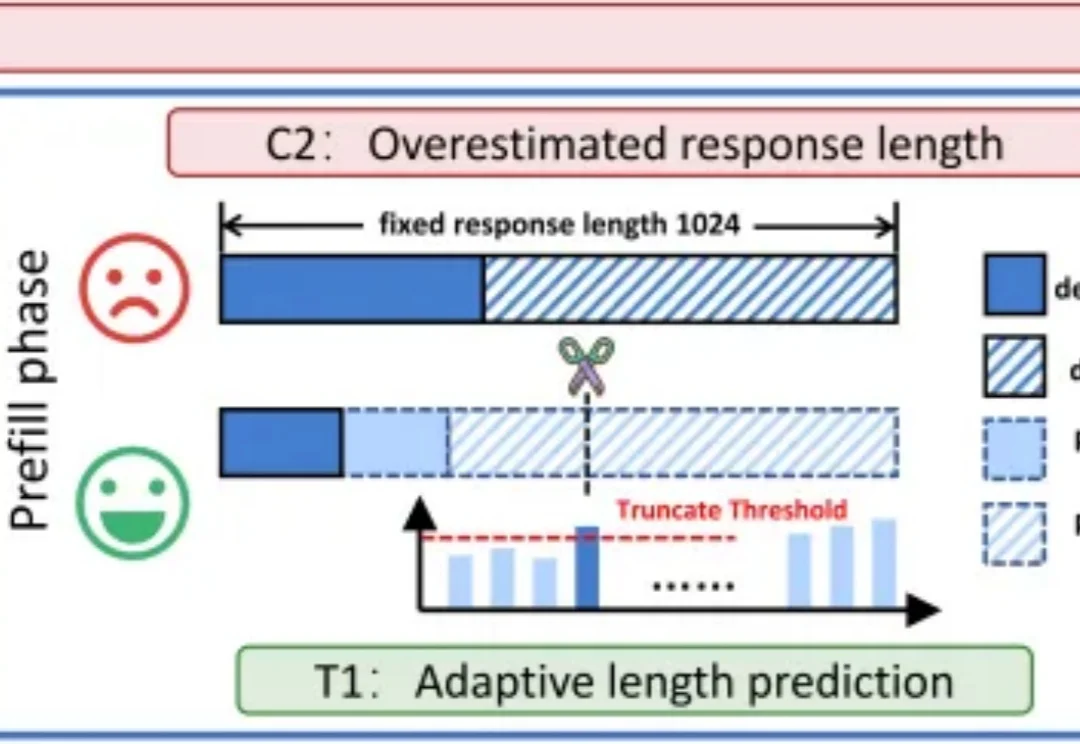
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。

在本周一举行的 Open Source Summit Japan 主题演讲中,Linux 基金会执行董事 Jim Zemlin 抛出了一个耐人寻味的判断: “AI 可能还谈不上全面泡沫化,但大模型或许已经开始泡沫化了。”